缓存系统在游戏业务中的特异性
在中国的互联网诸多业务领域中,游戏一直是充当“现金牛”而存在的。但是,在游戏服务器端开发领域中的很多重要问题,并没有被明确的分辨出其特异性,从而得到专门的对待。我们不管是在业界开源领域,还是内部分享中,很少会有专门针对游戏业务特征进行专门设计的组件、类库或者框架。我们从游戏的客户端方面来看,一款专业的游戏客户端引擎,已经是游戏开发的标配,比如最早的flash builder,到后期的cocos2d-x、unity、unreal;但是服务器端,我们几乎找不到同样重量级的产品。
在游戏服务器端开发所有要面对的问题中,有两个是最核心和最普遍的:一是和客户端的通讯;二是游戏登录用户的数据处理。对于和客户端通讯的这个问题,大量的游戏开发者会使用“通用”的开源组件,比如protocol buffer、thrift、jetty、node.js等等通信或rpc框架。虽然针对游戏,还是要做大量的改造,但一般都有很多现成的代码可供修改。但是对于第二个问题,不管是memcache还是mysql,或者是redis,都不能完全满足游戏开发者的需求。很多团队尝试过各种组合和修改,试图创造出利用现有开源软件,建设既能迎合灵活的需求变化,又具备高延迟和高可用的数据处理系统,但最后这些努力基本上都很难圆满成功。因此我们在游戏服务器端代码中,还是充斥着大量的内存、缓存管理,数据同步、落地等等代码。而且每个游戏都要重新去写一遍这些类似的功能,不能不说一种浪费。
如果我们要想出一种能满足“游戏”这个业务领域的数据系统设计,那么就一定要搞清楚为什么在如此之多的开源项目和游戏团队中,没能实现完美契合的原因。
电子商务/一般互联网类业务的数据处理流程
memcache、redis、mysql在一般互联网业务中的应用非常广泛。而且基本上能很好的应对各种常见的应用场景,包括类似bbs的社区、新闻门户、电子商务类系统。在企业内部信息系统中(intranet),这一类数据软件也能发挥非常好的功效。由于电子商务类是其中最复杂的系统,所以我在这里以此为例说明,一般数据处理的流程是如何的。
假设我们浏览了一个网店,选中了一个商品,点击了下单这个流程,实际上需要的后台流程可能是下图所示:
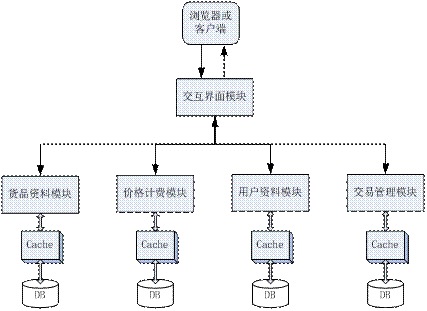
从上面的分析大概可以总结出几个特点:
忍受延迟: 每个操作的延迟要求较低,操作频率不会太高。一般我们页面在5秒内打开,都不会引起太多客户的抗议。所以,就算我们处理一个请求的时候,后台进行多次的进程间调用,产生的延迟和带宽消耗也是可以忍受的。
在线交互少: 互联网业务大多数是基于浏览器的,所以在线用户之间很少实时交互。
数据分散: 一般来说,互联网应用的数据可以在多个不同的业务系统中共用,但是需要专门的业务模块来做管理,以维持数据的一致性。
数据变更面广: 系统需要持续处理很多数据变更,互联网业务有很大一部分数据是来源于普通用户、网络编辑、店主等等使用者,在使用的过程中,他们会大量的修改系统所存储的数据。
以上四个特点,导致了我们一般会把后台要处理的数据,分别用cache系统和db系统来处理。并且,我们一般会按业务功能划分模块,同时也划分业务系统。由于延迟和在线交互的需求较弱,所以使用大量进程来做模块隔离,依然是非常可行的,总体来说,就是一种比较“分散”的数据使用方式。
游戏类业务的数据处理流程
在各种游戏中,mmorpg是数据处理最为复杂的一类,也是最典型的一种“重服务器端”的游戏类型,因此可以作为游戏业务中通用性的参考标准。在mmorpg中,我们可以发现,数据的处理需求,和一般互联网业务大相径庭,它体现出的是一种明显的“集中”式的数据处理需求。
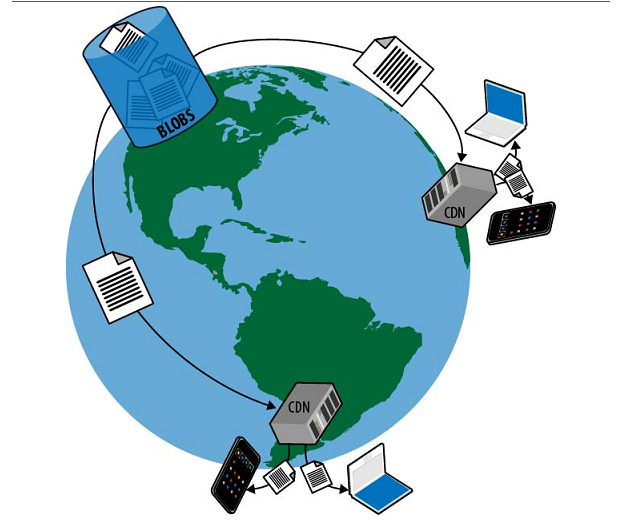
在游戏业务中,一般我们都会发现以下的特点:
延迟敏感: 游戏中用户会产生大量操作,都要求“实时”进行反馈,所以一般都不能忍受1秒以上的延迟,在大量动作类型的游戏中,一般都会要求服务器的反馈时延在50ms左右。因此游戏开发者都习惯于尽量减少后台进程间的交互,尽管这对提高系统吞吐量很不利。所以大部分游戏服务器端都有一个所谓“gameserver”,里面运行了游戏70%以上的功能。
大量实时交互: 在线游戏的特点,就是很多玩家可以通过服务器“看见”彼此,能实时的互动。因此我们必须要把用户的在线数据,集中到一起,才能提供互相操作的可能;而且a用户操作b用户的数据,是最常见的数据操作,所谓战斗玩法,就是互相修改对方的数据的过程。
数据集中: 游戏是一个几乎完全虚拟的世界,在游戏中的数据,实际上很少能在其他系统中产生价值。而游戏逻辑也禁止通过游戏以外的方式,修改游戏的数据。所以游戏中的数据,一般都会集中存放在单独的数据库中。由于没有数据共用的需求,所以也不需要把gameserver里面集中的逻辑划分出很多单独的进程模块来。
数据变更少: 实际上游戏的数据变更还是很快的,比如游戏中的每次中弹,都要减少hp的数值。但是游戏里的数据,一般都遵守这样一个规则:“变化越快的数据,重要性越低”。也就是说,游戏中是可以容忍一定程度的数据不一致和不完整的。而游戏中的数据,一般会分成两类:玩家存档和游戏设置。对于玩家存档来说,其单条数据量一般不大,但会有大量的记录数,因为每个玩家都会有一个存档。但是其读取、修改,一般很典型的和玩家的登录、登出、升级等业务逻辑密切关联,所以其缓存时机是比较容易根据业务逻辑来把握的。而对于游戏设置数据来说,几乎只有升级游戏版本的时候才会修改,大部分运行时是只读的,其缓存简单的读入内存就解决问题了。
一般的缓存系统的特点在游戏中的问题
根据以上的分析,我们可以看到,普通的缓存系统,如memcache和redis,实际上其特点是不太适合游戏业务的:
一般跨进程的缓存系统,无法解决游戏要求的低延迟问题。级别是同机房,每次数据存取都需要10-20ms的时间,对于游戏战斗中大量的数据读、写来说,是很难接受的(但是一些回合制战斗、低频操作还是有用的)。
通用型的缓存系统或者数据库,一般都比较难集结多个进程,形成一个完整的数据存储网格。这让玩家间的互相交互产生了额外的难度,开发者必须先想办法确定玩家的数据在哪个后台进程上,然后才能去读写。一般的数据库或缓存系统,为了保证数据的一致性或者完整性,往往会需要牺牲一些分布式的能力。而这种牺牲在游戏业务中,其实是一种浪费,因为游戏的很多数据都无需这种能力。
通用性数据系统一般不依赖于特定的语言,所以很少能直接把某种“对象”存入到数据系统中。在游戏开发中,需要存储的数据结构数量往往是非常大量的:一个普通的游戏,基本上都会超过100种数据结构。对于每个数据结构,都去建表或者编写序列化/反序列化配置,是一种非常累人的工作。——明明在代码中,已经用编程语言定义了他们的结构,还要重复的搞一次。
根据上面说的这些问题,我们实际上是需要另外一种完全不同设计思想的数据系统。
本地分布式缓存服务的特点和优势
对于游戏业务来说,一个好用的数据系统,应该包括这样一些特点:
可以利用gameserver进程内的内存进行自动化的缓存管理。由于gameserver进程往往集中了大部分的逻辑运算,所以大部分的数据缓存也应该在这个进程中,这样才能符合游戏所需的延迟要求。
自动进行数据落地和容灾管理。由于游戏数据中有大量的“过程数据”,所以其一致性和完整性要求会稍微低于其他业务,所以应该利用这一点,让gameserver本身也可以是分布式的程序,从而提高系统整体的吞吐量。
具备良好的编程易用性。最好是能直接存取编程中的对象,避免反复对数据结构的描述,节省大量的开发时间。
